Integrating a print-friendly and web-friendly resume into an Astro website
- Michael Alonge
- Web Development , Software Engineering , Career
- 15 Jan, 2025
My personal website needed a makeover. In 2021, while I was a Ph.D. student, I built a static site with Jekyll and hosted it on GitHub Pages. While it served me well, it was time for an updated look that reflected my style and professional persona. I’ve been having a great experience using Astro with the Astroplate template for my new static personal website. At first, there was nothing especially noteworthy about the experience — just some basic customization and extension of the original template. Then it came time to add a resume page, and I ran into an interesting dilemma: how should I present my resume?
The problem: three imperfect approaches
Option 1: Provide a download link for a PDF
This involves precompiling a PDF and hosting it on my site with a download link. But with this approach none of my resume content gets embedded in the page HTML, which is bad for search engine optimization (SEO). Further, I want users to see my resume ASAP with as few clicks as possible.
Option 2: A full typeset resume web page
I could typeset my resume in HTML and CSS and serve it as a standalone page. But this approach breaks the site’s navigation flow. Visitors would lose the menu and footer and all the other bells and whistles of my astro site layout. I didn’t want the resume page to feel like a completely separate experience from the rest of my site.
Option 3: Just another Astro page
I could treat my resume as just another content page within the Astro project. But then I’d lose all the benefits of proper typesetting and print-specific styling that makes a resume look professional when printed.
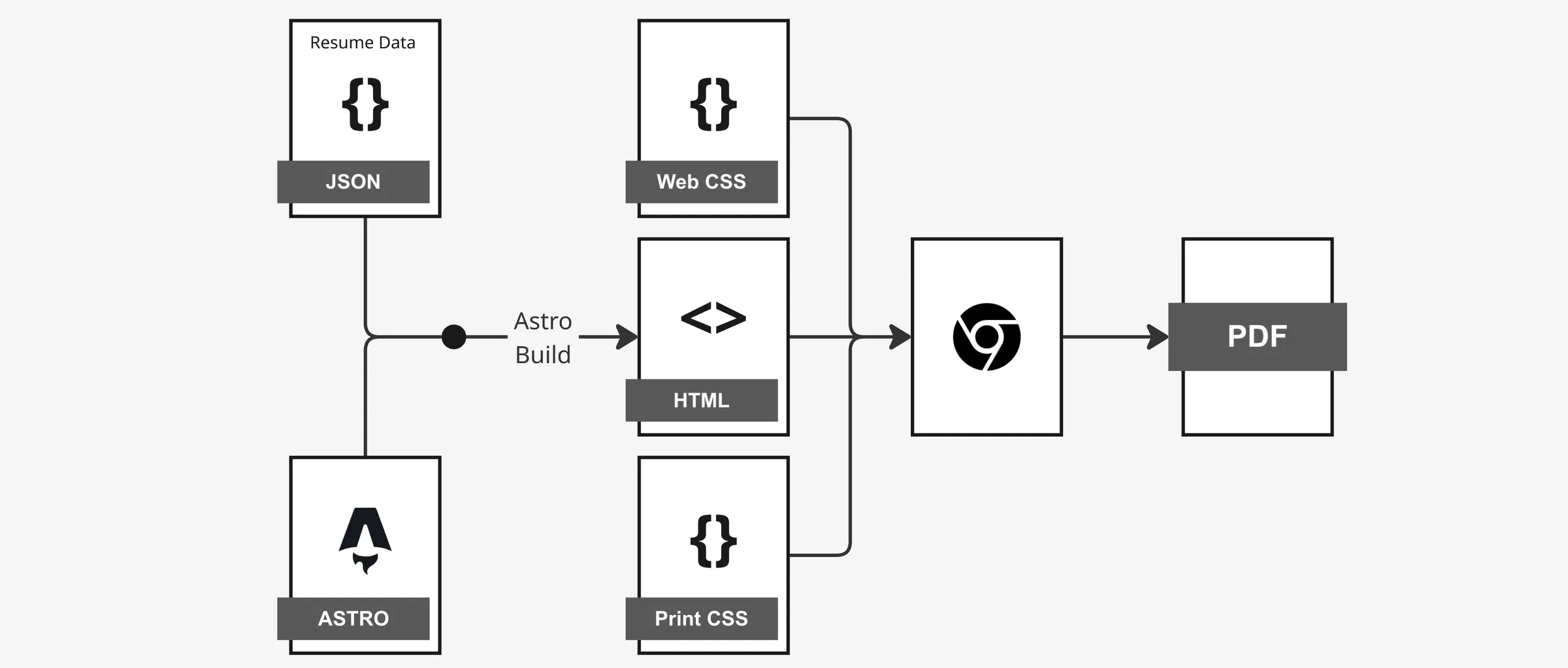
The solution: a dual-purpose resume system
I wanted a resume page that seamlessly integrates with my site’s design while embedding the resume data directly in the HTML for SEO. But I also needed it to generate professional, print-ready PDFs that recruiters would love. The solution was a dedicated page that maintains the site’s base layout while dynamically injecting a web-friendly resume into the content area. A print button enables users to generate optimized PDFs, with the page dynamically switching between web and print styles. Here’s how I built it!
Step 1: Decoupling data from presentation
To start, I knew that my resume content — the data — should be independent from how it’s styled and formatted. This follows fundamental software engineering principles: separation of concerns, single sources of truth, and configuration-driven design. I chose the JSON Resume standard for my data schema. It’s a widely adopted, well-documented format that’s easy to parse and extend. Here’s a snippet showing how I structured my resume data:
{
"basics": {
"name": "Michael Alonge",
"label": "Software Engineer | Computational Biologist | Team Lead",
"email": "malonge11@gmail.com",
"profiles": [
{
"network": "LinkedIn",
"username": "michael-alonge",
"url": "https://www.linkedin.com/in/michael-alonge"
}
]
},
"work": [
{
"name": "Ohalo Genetics",
"position": "Lead Software Engineer, Computational Biology",
...
}
],
"education": [
{
"institution": "Johns Hopkins University",
"area": "Computer Science",
"studyType": "Ph.D.",
...
}
],
"publications": [
{
"name": "The complete sequence of a human genome",
"publisher": "Science",
"releaseDate": "2022"
}
],
"skills": [
{
"name": "Google Cloud & Cloud Engineering",
"keywords": [
"Cloud Run",
"Cloud Functions",
"Compute Engine"
]
}
]
}With this decoupled structure, I can add new experience entries and the format updates automatically. Conversely, I can completely redesign the styling without touching the data. This makes the system maintainable and extensible.
Step 2: Typesetting with HTML and CSS
HTML and CSS were the obvious choice over LaTeX for typesetting. They’re more powerful, flexible, and integrate seamlessly with my existing Astro site. I found inspiration in Min–Zhong John Lu’s excellent HTML/CSS resume template, which has clean, professional styling and well-organized code. I adapted the template by replacing hard-coded data with dynamic content from my JSON file using Astro’s component syntax. The resume content slots directly into my site’s base layout. Here’s how the publications section works:
---
import Base from "@/layouts/Base.astro";
import "@/styles/cv.css";
import { ..., FiBook, ..., FiBookOpen } from "react-icons/fi";
import cvData from "@/config/cv.json";
---
<Base title="CV">
...
<div class="cv-container">
...
<section class="main-block">
<h2>
<FiBook className="cv-icon" /> Selected Publications
</h2>
{cvData.publications.filter(pub => pub.selected).map((publication) => {
const releaseYear = publication.releaseDate;
return (
<section class="blocks">
<div class="date">
<span>{releaseYear}</span>
</div>
<div class="decorator">
</div>
<div class="details">
<header>
<h3>
{publication.name}
{publication.firstAuthor && <span class="first-author-note"> (first author)</span>}
</h3>
<span class="place">{publication.publisher}</span>
</header>
<div>
{publication.summary && publication.url && (
<p>{publication.summary} — <a href={publication.url} target="_blank" rel="noopener noreferrer">{publication.url}</a></p>
)}
{publication.summary && !publication.url && (
<p>{publication.summary}</p>
)}
{!publication.summary && publication.url && (
<p><a href={publication.url} target="_blank" rel="noopener noreferrer">{publication.url}</a></p>
)}
</div>
</div>
</section>
);
})}
</section>
</section>
...
</div>
...
</Base>The beauty of this approach is that adding a new publication to config/cv.json automatically updates the HTML page. The base layout is preserved by simply wrapping the resume content in the <Base> component. Now I have a typeset, SEO-friendly resume page that’s easy to maintain.
Step 3: Print-optimized PDF generation
The web-friendly resume is great for SEO and user experience, but recruiters often need downloadable PDFs. While browsers can save web pages as PDFs, our web page is not configured for printing. If one were to print the resume web page as is, the content would be cut off, margins would be wrong, and unnecessary elements like navigation menus would get included.
My solution was to trigger custom CSS when the user prints the web page. First I added a prominent “Print/Download Formatted CV” button at the top of the resume page that triggers window.print(). This browser function is universally supported and gives users a one-click way to generate PDFs without navigating menus. Then I implemented dual styling systems: one for web viewing and another for print. When users click the print button, CSS media queries kick in to hide navigation elements and apply print-optimized layouts. Here’s the key CSS that makes this work:
/* Print styles - hide website header/footer and apply CV layout */
@media print {
/* Hide website navigation elements but keep CV header */
body > header,
header[class],
.header,
nav,
footer,
.footer {
display: none !important;
}
/* Ensure CV header (title section) remains visible */
#title,
#title h1,
.subtitle {
display: block !important;
visibility: visible !important;
}
/* Reset body for print */
body {
width: var(--page-width) !important;
height: var(--page-height) !important;
margin: 0 !important;
padding: 0 !important;
font-family: "Open Sans", sans-serif !important;
font-weight: 300 !important;
line-height: 1.3 !important;
color: #444 !important;
hyphens: auto !important;
background: white !important;
-webkit-print-color-adjust: exact !important;
print-color-adjust: exact !important;
}
/* Reset main content wrapper for print */
#main-content {
padding: 0 !important;
margin: 0 !important;
max-width: none !important;
}
}I minimized code duplication by extracting common styles into shared stylesheets, making the system easier to maintain and extend.
Technical decisions and architectural insights
Data schema design
While I could have designed a custom schema, the JSON resume standard provides several advantages. It’s battle-tested, well-documented, and has a growing ecosystem of tools. More importantly, it enforces a clean separation between content and presentation. The schema’s hierarchical structure (basics, work, education, publications, skills) maps naturally to how humans think about professional information, making it intuitive for content editors while maintaining programmatic flexibility. I can easily extend it with custom fields like selected and firstAuthor for publications or level for skills without breaking the core structure.
Rendering architecture
I chose window.print() over client-side PDF libraries like jsPDF for several reasons. First, it leverages the browser’s built-in PDF engine, which is very mature and produces consistent, high-quality output across different devices. Second, it eliminates dependency on heavy PDF generation libraries that would increase my site’s load time. Third, it’s future-proof. As browsers improve their PDF engines, my solution automatically benefits without code changes. Server-side rendering was never an option since my entire site is static. This constraint actually led to a better solution because by keeping everything client-side, the PDF generation is instant and doesn’t require any server resources or API calls.
Performance considerations
Since the resume data is embedded in the page HTML at build time (Astro pre-renders everything), there’s zero runtime overhead for visitors. The CSS media query approach for print styling is also performant because there is no JavaScript execution needed during PDF generation. The browser’s CSS engine handles the style switching efficiently, and the !important declarations ensure print styles take precedence without complex specificity calculations.
Scalability and extensibility
This architecture scales well beyond just resumes. The same pattern could handle any structured content that needs both web and print representations: research papers, technical documentation, or even complex reports. The JSON schema is easily extensible or you could make a custom schema, and the CSS print system can be adapted for different document types. The component-based approach also makes it easy to add new resume sections or modify existing ones. Want to add a “Certifications” section? Just extend the JSON schema and add the corresponding HTML template. The styling automatically adapts thanks to the shared CSS classes.
The result: a professional, maintainable resume system
This project demonstrates how applying solid software engineering principles to everyday problems can yield elegant solutions. While there’s upfront effort in designing and implementing the system, it pays dividends in maintainability and user experience.
The dual-purpose approach gives me the best of both worlds: an SEO-friendly web page that integrates seamlessly with my site, and a professional PDF generator that produces recruiter-ready documents. The JSON-based data structure makes updates trivial as I can add new experience, publications, or skills without touching any formatting code.
Check out the source code on GitHub here and the live resume page here. The system is open source, so feel free to adapt it for your own projects!